Bei einem unserer Projekte sind wir kürzlich auf ein unerwartete Performance-Problem in JavaScript gestoßen: Wir wollten zwei große JSON-Logdateien miteinander vergleichen und diejenigen Zeilen herausfiltern, welche in beiden Logdateien enthalten sind. Eigentlich ist das eine gängige und simple Aufgabe und mit wenigen Zeilen JavaScript erledigt. Mit dem Suchbegriff “Mengenoperationen JavaScript” findet man auch schnell die üblichen StackOverflow-Beiträge mit vermeintlichen Lösungen für diese Aufgabe zum Thema “Differenzmenge”. Bei kleinen Dateien werden alle gefundenen Lösungen auch keine Probleme machen, aber in unserem Fall ging es um JSON-Arrays mit ca. 1.000.000 Objekten/Zeilen. Als eine der vorgeschlagenen Lösungen nach über einer Stunde Laufzeit immer noch nicht fertig war, machten wir uns langsam Gedanken und haben ein paar Alternativen miteinander verglichen.
Mengenoperationen erst seit 2024 im Standard verfügbar
JavaScript bzw. ECMAScript (der “richtige” Name der Sprache) brachte lange Zeit keine expliziten Funktionen für Mengenoperationen mit. Obwohl diese Funktionen schon lange diskutiert wurden, erreichten sie erst 2024 die “Stage 4”, wurden also offiziell in den Standard aufgenommen. Seit einigen Monaten gibt es nun also in den meisten Runtimes explizit die Möglichkeit, Mengenoperationen wie .union(), .intersection() und .difference() an Set-Objekten berechnen zu lassen. Im Internet findet man aber natürlich oftmals noch Code, welcher für diese Aufgabe kein Set verwendet. Wir haben also alte und neue Optionen miteinander verglichen:
Vorbereitung: Wir bauen uns zwei große Arrays
Für die folgenden Vergleiche haben wir jeweils die gleichen zwei Arrays mit einer beispielhaften Länge von 200.000 Elementen initialisiert. Der Inhalt dieser Objekte spielt hier keine besondere Rolle. Nur so viel: Sie enthalten jeweils eine ID, über die sie eindeutig identifiziert werden können. Wir suchen also in beiden Arrays diejenigen Objekte mit der gleichen ID.
const bigArray1 = Array.from(
{ length: 200000 },
(v, k) => ({ id: k.toString() }),
);
const bigArray2 = Array.from(
{ length: 200000 },
(v, k) => ({ id: (k / 2).toString() }),
);
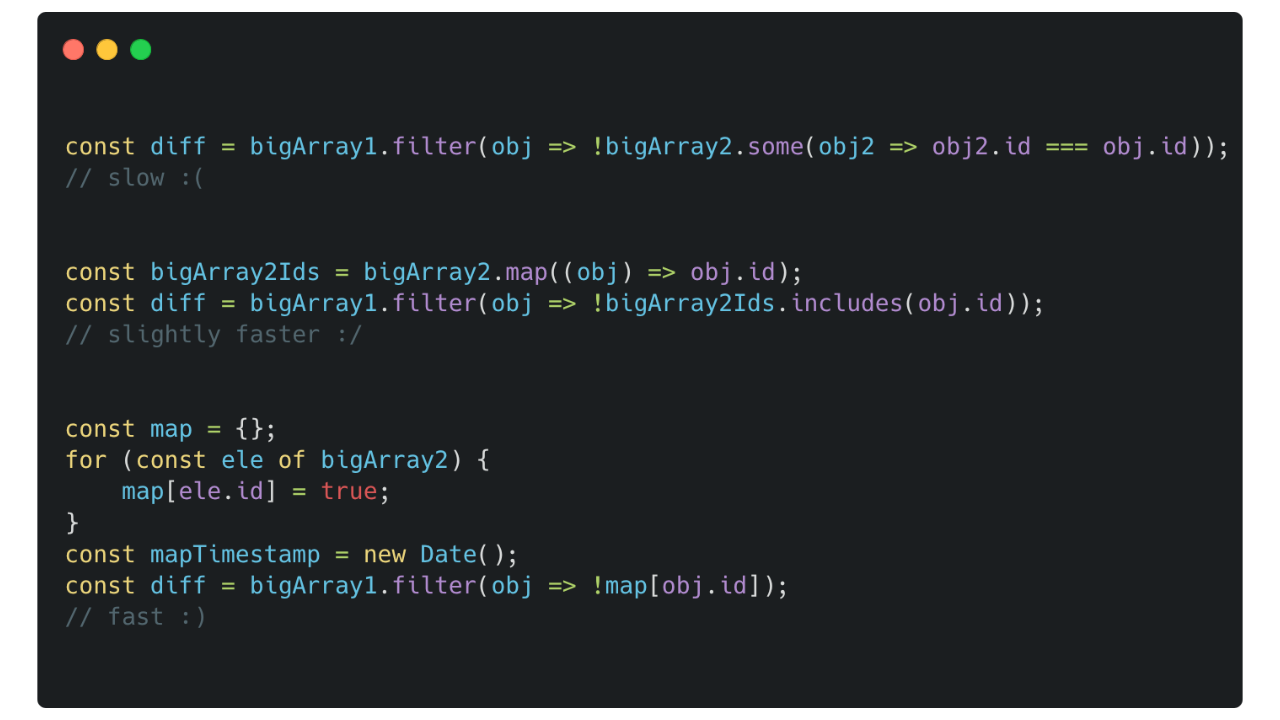
Vergleichen mit Schleifen oder .filter() und .some()
// Option 1a
const diff = bigArray1.filter(
(obj) => !bigArray2.some((obj2) => obj2.id === obj.id),
);
// => Dauer ~120 s
// Option 1b
const diff = [];
outerLoop: for (const array1Element of bigArray1) {
for (const array2Element of bigArray2) {
if (array1Element.id === array2Element.id) {
continue outerLoop;
}
}
diff.push(array1Element);
}
// => Dauer ~120 s
Dieser Code war unser erster, naiver Ansatz zum Bilden der Differenz: Die Verwendung von .filter() ist ein klassisches Konzept aus der funktionalen Programmierung. Der Code ist kurz und gut verständlich und es wird dabei relativ wenig Speicher verbraucht. Der Nachteil dieser Variante ist aber, dass relativ viel Zeit benötigt wird. Der Aufwand für die Laufzeit dieses Algorithmus wird als O(n²) beschrieben – das heißt, jedes Array-Element des ersten Arrays wird mit jedem Array-Element des zweiten Arrays verglichen (also in diesem Fall finden 200.000² = 40 Mrd. Vergleichsoperationen statt). Auch die zweite Code-Variante basiert genau auf diesem Grundsatz, benutzt jedoch zwei for-Schleifen statt dem funktionalen filter()-Aufruf und braucht deswegen etwa genau so lange für die Berechnung. Beide Varianten sind also nur dann sinnvoll, wenn wenig Arbeitsspeicher zur Verfügung steht oder die beiden Arrays eine Größe haben, bei denen die Laufzeit egal ist.
Ein Array von IDs und Array.includes()
// Option 2
const bigArray2Ids = bigArray2.map((obj) => obj.id);
const diff = bigArray1.filter(
(obj) => !bigArray2Ids.includes(obj.id),
);
// => Dauer ~80 s
Bei der zweiten Option haben wir Array.includes() benutzt, um zu prüfen, ob eine Logzeile in dem Array vorhanden ist. Da includes() die Referenzen der Objekte vergleicht, und nicht deren Inhalt, müssen wir hier die IDs statt der kompletten Objekte benutzen. Deswegen erstellen wir zuerst ein Array mit allen IDs von einem der beiden Logfiles und sortieren dann diejenigen Einträge aus dem zweiten Logfile, deren IDs bereits im ersten Array enthalten sind. Die Laufzeit verbessert sich in diesem Ansatz etwas, dafür ist nun der Speicherbedarf höher, da wir ein zusätzliches Array mit den IDs benötigen. Diese Variante ist vielleicht etwas weniger intuitiv als die erste Variante und der Laufzeit-Vorteil ist relativ gering.
Sets mit JSON.stringify()
// Option 3
const bigArray2StringifiedSet = new Set(
bigArray2.map((obj) => JSON.stringify(obj)),
);
const bigArray1StringifiedSet = new Set(
bigArray1.map((obj) => JSON.stringify(obj)),
);
const differenceStringified = Array.from(
bigArray1StringifiedSet.difference(
bigArray2StringifiedSet,
),
);
const diff = differenceStringified.map((obj) =>
JSON.parse(obj),
);
// => Dauer ~0.4 s
Nun verwenden wir endlich die “neuen” Mengenoperationen (konkret die .difference()-Operation). Diese arbeiten aber nur mit Sets: das heißt wir müssen beide Arrays zunächst in geeignete Sets überführen. Da aber auch hier Referenzen von den jeweiligen Objekten verglichen werden würden, benutzen wir nun JSON.stringify(), um vergleichbare Strings aus den Objekten zu erzeugen. Der Haken hier dran ist, dass beide Objekte die gleichen Eigenschaften haben müssen – die gleiche ID reicht nicht aus. Alternativ könnte man die Mengenoperation auch nur auf die zwei Sets der IDs anwenden. Dann müsste man im Nachhinein aber wieder die verbleibenden IDs zu ihren ursprünglichen Objekten auflösen – was in Summe langsamer ist, als dieser JSON.stringify()-Ansatz. Hier stellen wir nun das erste mal einen deutlichen Sprung in der Laufzeit fest. Die Komplexität des Algorithmus sinkt nämlich wahrscheinlich auf O(n) (abhängig von der Implementierung in der jeweiligen JavaScript-Engine). Der Speicherbedarf ist allerdings auch deutlich gestiegen, da wir beide Arrays nicht nur duplizieren, sondern auch als serialisierte Strings im Speicher halten.
Am schnellsten: Objektfelder als Lookup-Table
// Option 4
const map = {};
for (const ele of bigArray2) {
map[ele.id] = true;
}
const diff = bigArray1.filter((obj) => !map[obj.id]);
// => Dauer ~0.07 s
Die mit Abstand schnellste Variante ist es, ein Objekt als eine einfache “Lookup Table” zu benutzen. Hierbei erzeugen wir für jede ID des einen Arrays ein Feld in einem neuen Objekt. Somit wird zusätlicher Speicher für diese Tabelle benötigt – allerdings nur in der Größe von n (= Anzahl der Element im Array) * 2 Bytes (ein Boolean in JavaScript ist üblicherweise ein Byte groß). Beim Vergleichen der Werte kann dann auf die vorgefertigte Tabelle zugegriffen werden. Der Zugriff auf die Tabelle hat eine Laufzeitkomplexität von O(1), somit hat das Filtern eine Komplexität von O(n). Diese Variante ist deutlich schneller als alle anderen Herangehensweisen. Allerdings mag der Code für einige Entwickler (die keinen Background in hardwarenaher Programmierung haben) etwas ungewöhnlich aussehen. Für performantes Vergleichen von zwei solcher Arrays ist diese Variante allerdings klar zu bevorzugen, solange genügend Arbeitsspeicher vorhanden ist.
Fazit: Überall Footguns, auch bei Mengenoperationen
Wie so oft in der Informatik gilt auch hier: Vorteile in der Laufzeit bedeuten leider fast immer Nachteile im Speicherbedarf. JavaScript macht es mit seinen neuen Mengenoperationen sehr einfach, solche Operationen auszuführen. Oftmals ist diese “naive” Herangehensweise allerdings nicht sehr performant – es handelt sich also um eine sogenannte “Footgun” (etwas vermeintlich Einfaches, bei dem sich der Entwickler sprichwörtlich in den Fuß schießen kann). Bei großen Datenmengen lohnt sich definitiv der Blick auf andere Algorithmen, da die Zeiteinsparungen ein Vielfaches (in unserem Beispielfall: Faktor 170) betragen können.